DQNsort
Sorting with neural nets
Aug 23, 2019
A famous saying goes: There are many ways to skin a cat. These are words that apply especially well to sorting arrays. When asked to sort one, your sane person may immediately go with bubble sort, insertion sort, or perhaps the very lovely and very fast quicksort. The show-offs like to call out radix sort and the jokers always point out bogosort and Stalinsort. Today, however, I present to you something new, pulled entirely out of my limited machine learning knowledge. Yes, ladies and gentlemen, it’s DQNsort!
Background
Reddit’s r/programminghumor was holding a hackathon with the theme “Overengineering”. I had long dreamed of getting into reinforcement learning after watching many of Siraj Raval’s videos on the subject, so this was the perfect time to try to play around with it, and what a better thing to overengineer than a sorting algorithm! It does look like, however, that sorting using reinforcement learning is not a new idea. A paper has already been written describing RPsort which appears to use a more advanced version of RL that generates algorithms in a process called reinforcement programming, but that’s beside the point.
RL in a Jiffy
Reinforcement learning, in general, trains an AI agent to make optimal decisions in an environment. An environment has a state and the agent is allowed to make actions to change this state. The environment gives the agent some amount of reward based on the agent’s choosen action. The goal of RL is to train an agent to learn a policy, or a function that chooses the most optimal action given a state.
A naive agent may have a policy that simply picks whatever action has the max immediate reward at every state, but this is not ideal since this agent becomes too short-sighted and won’t try to go for better long-term rewards. Reinforcement learning agents usually use a better method of learning policies called called Q-learning. Q-learning uses a Q table that acts like a large reference sheet, keeping track of a score for the action taken at each state called a Q-value. Q-values are learned values that reflect both the reward for an immediate action as well as those taken in the future. The agent is able to learn these Q-values by interacting with the environment and updating the Q table.
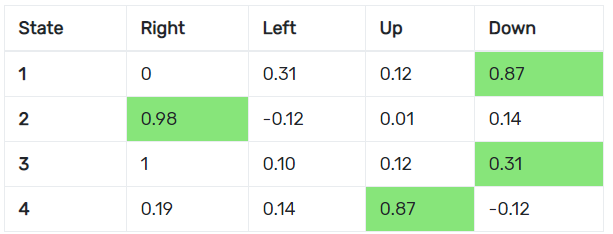
The problem with traditional Q-learning is that these tables take up a lot of space. Imagine you’re trying to build one for chess: There are millions of possible board states and tens of actions that could be made at each of them! It would be really nice if we could just create a function that took in a state and told us the Q-values of each action, and thanks to deep learning, we can do just that. Deep reinforcement learning is like traditional RL except this time, we’ve swapped the Q table for a neural net called a deep Q network or DQN that allows us to input a state and estimates the Q-values for each action.
Sorting with a Net
The DQNsort agent works by using a DQN to decide which two elements in an array to switch to get it closer to being sorted. The DQN is a multilayer-perceptron that takes an n-length array as a vector for its state and spits out a n^2-long vector that encodes the Q-values for all possible switches that can be made.
I had initially played around with multiple reward functions that did not rely on knowing that a certain element belonged in a certain place, such as rewarding based on the number of ascending elements, but these did not perform very well. I eventually settled on rewarding the agent if it made a change that put an element in the right place, penalizing it for doing the opposite, and adding an additional reward for sorting the array. Visdom was also added early on since I wanted a way to visualize the sorting process and graph the loss from the DQN in real-time.
With everything set, I started testing my agent, and, to no-one’s surprise, it was awful. Although the DQN’s loss went down over time, DQNsort never actually managed to sort anything, opting to repeatedly switch two elements. Searching online for solutions, I came to learn about replay memory. Instead of plugging in one state vector into our DQN, replay memory allows us to do batch training by keeping track of past states from which we sample from and feed into our DQN. However, even after adding replay memory, DQNsort was still doing the same thing. Something was still amiss.
I spent several days double checking my implementation and trying out new reward functions. Scouring the internet once again, I found a possible reason for my poor results: Lack of exploration. Training an RL agent comes in two phases: Exploration and exploitation. Exploration lets the agent randomly choose actions, giving it time to hit many states. Once the agent has explored enough, it switches over to exploitation, greedily choosing the action with the highest Q-value. My sorting agent did not strictly have these two phases. Instead, I had it set up to explore with a constant probability which was likely not allowing it to hit as many states as I needed. Doing a little bit of work, I changed DQNsort to start off with a high probability of exploration, dropping down to a low constant rate over time. However, DQNsort still did not improve after this change.
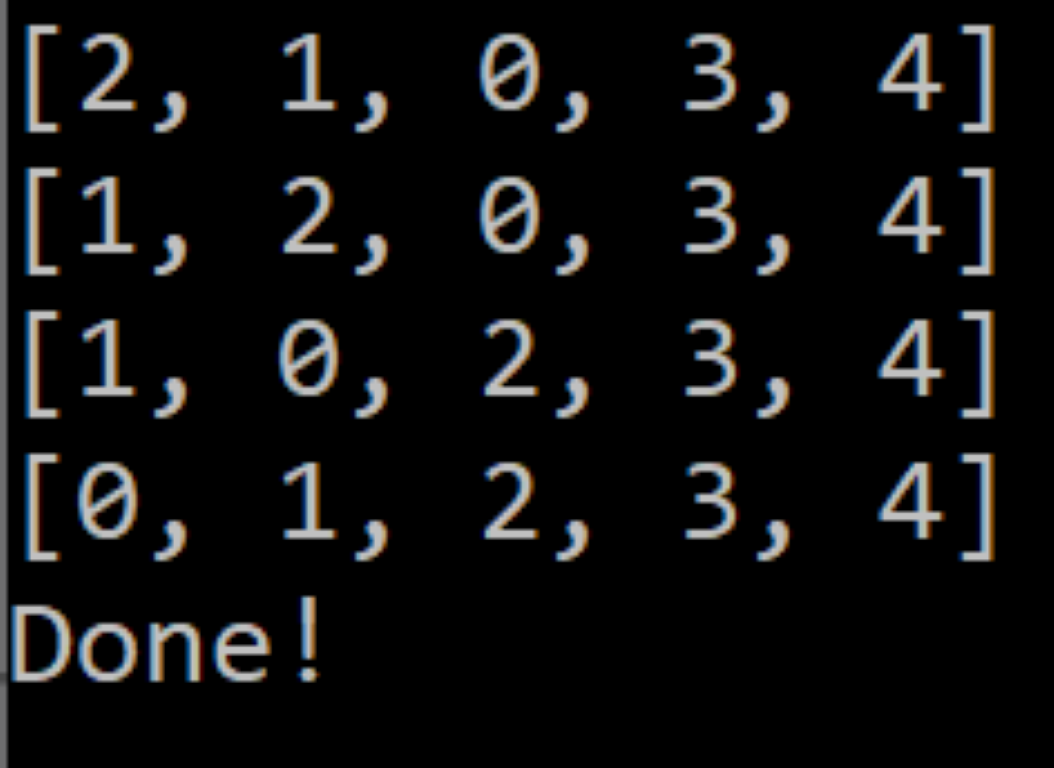
On a whim, I lowered the number of elements in the array from 10 to 5 and jacked the number of iterations to 10 million. The program started out training slowly as usual, but, after the 30th epoch, it suddenly shot through 50 more of them in an instant. No doubt about it. The only way it could do this was if it had actually learned how to sort! Training finished in under a few minutes, and I loaded the model into my test script with bated breath. It was still getting stuck on a few permutations, but for most cases, the agent had finally learned how to sort! The only changes I made after that were a few tweaks to some hyperparameters and the reward function to try to make it more reliable.
Problems and Improvements
The most tedious part of this project was figuring out what parameters DQNsort needed and the limits it could work within. Even after tuning it for several days, DQNsort is still not that robust.
A big problem with Q-learning in general is that it assumes an agent can visit every state and take every action an infinite number of times to refine the DQN. Reaching all 5 element permutations may have been fine for my agent, but scaling up to 10 elements was nearly impossible. Even at the current 5 elements, DQNsort still often runs into states that cause it to repeatedly take the same action, presumably because it simply has not seen that array configuration before.
DQNsort also rewards based on if the element’s value and its index in the array match. This means that it is only able to sort permutations of (0, 1, 2, 3, 4). This is not terrible if you treat sorting arrays as just another game, but compared to other sorting algorithms, DQNsort is not flexible at all.