The Nand2Tetris Experience
Turtles all the way down
Aug 18, 2021
I recently went through the Nand2Tetris course. The motivating goal behind the material is to learn about the foundational hardware and software components of a computer by building one from scratch. As the name suggests, the course starts you off with nothing but a NAND chip and, through a series of projects, helps you build your way up to being able to hypothetically program Tetris. Along the way, you get bite-sized tours of all the glue in between, everything from chip design to virtual machines to compilers, even to a very bare-bones operating system!
Chips Chips Galore!
The first half of the course consisted of defining the machine hardware. The general idea of these sections was to incrementally take previously-fabricated chips and build new, more advanced ones, ultimately culminating into our computer’s hardware.
Starting with the NAND chip, we were able to design and obtain a few basic logic chips. These chips, along with a pulsing clock, opened the door to several chains of fabrication that would lead us to a few necessary higher-order components. For instance, one chain went from adders to an ALU to a CPU, and another chain took us from flip-flops to registers to RAM. Once these higher-order components were made, we could finally assemble them as our machine, a very basic computer called Hack which could read and execute sequential instructions from a ROM. To make programming Hack easier, we also wrote an assembler to translate Hack assembly mnemonics into the actual program binary that gets loaded into ROM.
Looking back, despite the entire hardware section being a new experience for me, I was surprised to find that much of the chip designing felt natural and methodical. Once I had made additional logic chips from the starting NAND chip, many of the more complex components came together like pieces to a puzzle. Full adders could be chained together to make larger n-bit adders, and RAM could be doubled by recursively applying the same technique used to build the previous RAM chip.
Coming from the software side, there were many nuances to hardware that also took some getting used
to. One thing that became clear very quickly was that patterns learned from software do not always
translate to hardware. As an example, say you have 8 individually addressable slots of memory, and
you want to write a bit to a specific slot. Suppose in hardware, each slot takes two signals, one
that indicates an incoming value (new_value) and one that locks the slot, indicating whether it
should update its current value to the incoming value or not (should_write). In addition, suppose
all the slots are bused together. In hardware, to write to a certain slot, you would turn off
should_write for all slots except the target slot and then flood the incoming value to new_value
for all slots. From a software perspective, however, these 8 slots of memory would normally be
represented as an array. All a software programmer needs to do in such a scenario is target and
write to the slot via array indexing. Any notion of flooding or turning on and off locks from the
hardware implementation becomes lost to the software programmer.
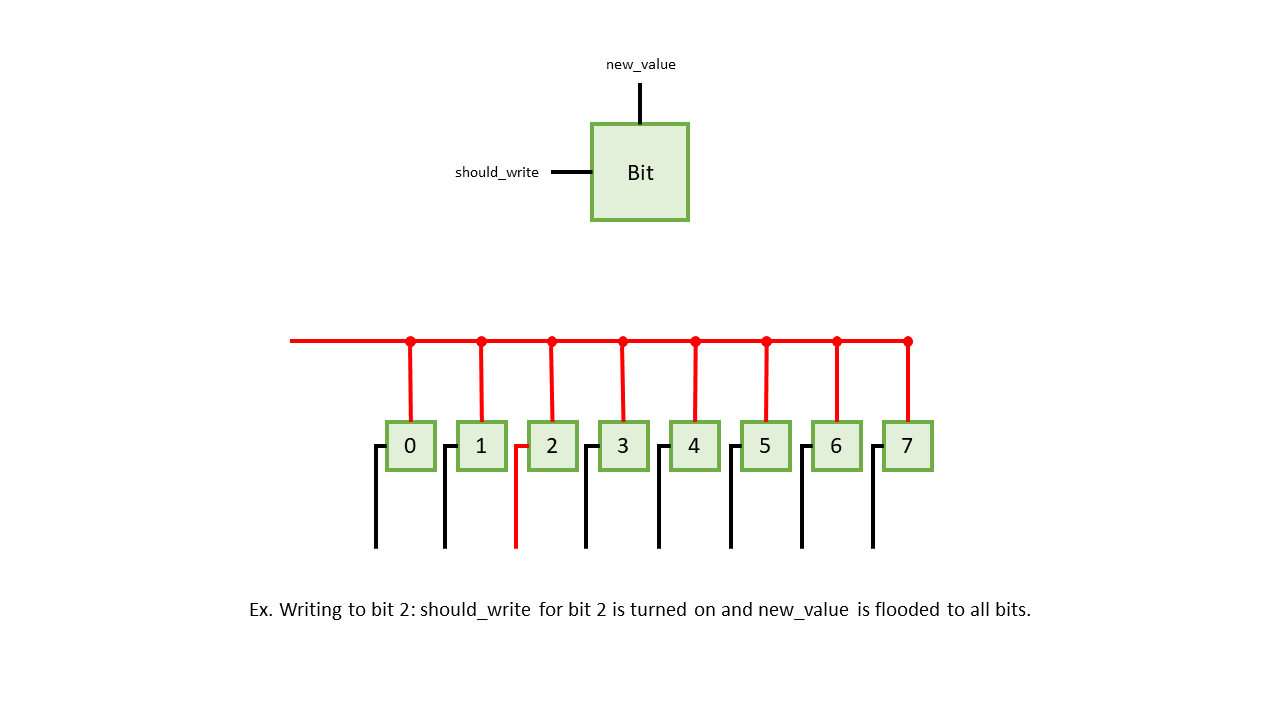
Having to change my mindset to work in a world of wires rather than bytes took some getting used to. I found that it was almost easier to run with the “electricity is like water” analogy and think about the circuits as plumbing rather than algorithms. Signal was water that I wanted to get to certain places and not others, and each gate changed the way the water flowed.
In the end, though, I finally managed to build my way up through all the hardware components to obtain a shiny, new virtual computer. With the hardware and assembler built, I could now begin the software section of the course.
Machine-to-Machine
The first thing we needed to address was the fact that our machine’s assembly language was still much too primitive. Our software suite was in dire need of a few more features, which leads us to the virtual machine (VM). In brief, the VM is an extra layer that sits directly on top of the Hack machine with the sole purpose of providing a few additional tools to make it easier to support higher level languages on our machine. For our VM, these tools were mainly a stack-based language, user-defined functions, and the concept of pointers.
Overall, the VM is important, primarily because it brings more ease with managing complexity. While we could have written a compiler that translates from a high level language directly to Hack assembly, building one without an intermediary is tougher and more error-prone than doing so with the VM layer in between.
Building a VM also has the added benefit of easy software portability. Suppose our VM happens to be a popular standard that was implemented on other computers as well. Software written for these other machines and compiled to the VM language can simply run on our VM implementation without any additional work1 which makes it easy to add new software to our ecosystem. This kind of portability benefit is perhaps best seen in a language like Java. All a new device needs to do to be able to run Java is implement the JVM for its hardware. Once that is done, as long as the specification for the JVM and Java bytecode do not change, the device can effectively run Java programs, even as Java itself continues to update.
Of course, getting a VM is not free either. We needed to implement all of our VM’s functionality in Hack which was done in the form of a VM language to Hack assembly translator. Once that was done, the next step was creating the final tool in the compilation toolchain: a high level language compiler.
The Compiler
In order to write programs for our computer in a language that was a little more user-friendly, we needed a compiler to translate the course’s high level language, Jack, into VM code. The Jack language provides a much more reasonable programming interface, resembling Java and C to some degree and providing familiar concepts such as types and classes.
Construction of the compiler was split into two parts: a lexer, which converts text into tokens, and a parser, which converts tokens into semantic meaning. The parser we had to make in particular was a LL(0) parser2 which means it parses tokens left-to-right, derives the leftmost non-terminal token, and looks ahead 0 tokens when determining how to proceed. Usually a parser generates an abstract syntax tree which is then passed off to other modules for compile-time checks, optimizations, and, ultimately, compilation. However, the scope of the course seemed to only ask us to generate code directly.
Working through it, the compiler ended up being quite a reasonable section despite its foreboding name. I had done similar projects for school, so this part was actually old news for me. Many of the VM’s abstractions also off-loaded the logic for the code that the compiler needed to generate by providing a stack and taking care of copying values to it during function calls. The biggest problems I ran into when writing the compiler were dealing with pointers and an issue where certain identifiers would be lexed as keywords. It turns out that the latter problem occurred because I was not lexing greedily which was easily fixed by comparing the lengths of potential tokenizations and proceeding with the one that consumed the most text.
Remembering to Forget
With a compiler for a high level language added to our tool belt, the final part of Nand2Tetris was to write an operating system (OS). Yes, my friends. A fully-fledged operating system just like Microsoft Windo-. In reality, all we needed at this stage for our operating system were a few foundational libraries to supplement the Jack language, handling basic features such as more advanced math, screen and keyboard IO, and memory management.
Of the modules I needed to write, I found the memory management one to be the most interesting. OS memory management was something I didn’t really have a clear understanding of before, so having the chance to finally write something that actually did it was quite exciting.
We were introduced to two ways to manage memory. The first way is a naive method where memory is never recycled. A pointer starts at the beginning of the heap and is incremented anytime memory is allocated. This, of course, will exhaust the heap very quickly over time.
The improved method asks us to, instead, allocate memory via blocks on a linked list. The list is implemented directly on the heap and consists of nodes that hold runs of memory. Whenever memory is needed, we find a block that contains enough space and split off a necessary amount of it for the requester. When memory is freed, the freed block is appended to the linked list, allowing it to be re-used on subsequent allocations. A program starts off with a list that contains one node representing the entirety of the heap. As memory gets allocated, the biggest node shrinks as blocks are split off, and, as memory gets returned, the list grows as broken off blocks are appended back on.
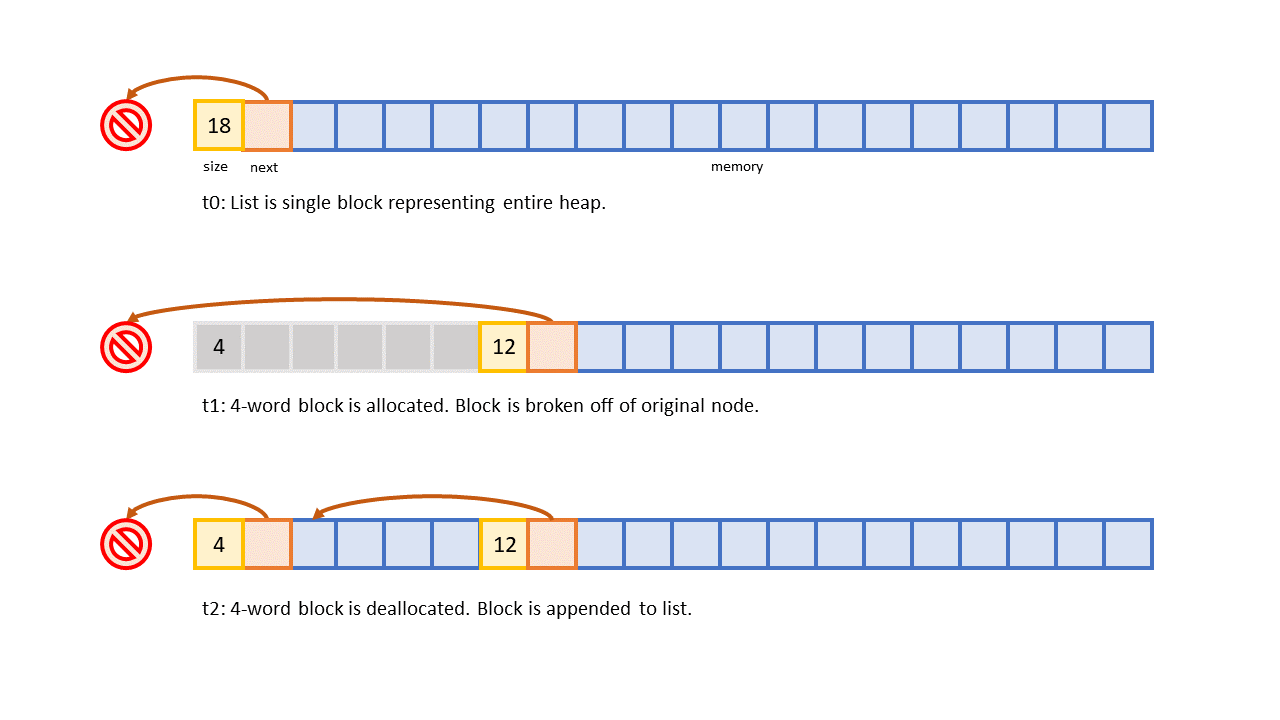
One problem with allocating blocks of memory like this is that you eventually run into memory fragmentation. The heap ends up becoming split into blocks of very small sizes, and it becomes impossible to allocate memory for bigger structures because no blocks are big enough to hold them. There appear to be a variety of methods to defragment memory by compacting free blocks in the heap, but doing so efficiently seems to be a complex endeavor.
While the memory module felt like the most complex part of the operating system, the other modules were non-trivial as well. Eventually, I managed to write out and test every module in the operating system, finally bringing my Nand2Tetris journey to an end.
Thoughts on the Course
Overall, I found Nand2Tetris to be fun and enlightening. It was interesting to see a lot of the lower level computing I generally don’t get to encounter, and the course gave me a much greater appreciation for the kind of effort that goes into making and maintaining lower level software (see appendix A).
Being able to see how a computer is made from the ground up was a very eye-opening experience for me. One of the most difficult concepts to grasp when I first started learning to program was understanding how computers worked from top to bottom. For all intents and purposes back then, the computer was magic in a box that could run Python and play Youtube. How my computer managed such complexity was unfathomable. Later in school, I had the chance to explore lower level languages like C and assembly as well as compilers. I learned about the compilation process and memory allocation which got me a little closer to seeing the bottom but still left me with many questions about how these lower level tools were made, and what existed that was even lower.
Although I am still peering down into that abyss today, I think that Nand2Tetris helped clear up a lot of the haze. The biggest benefit of the course is that it starts you at the bottom and asks you to build an alternative to what we have today. As you work your way up, you begin to see familiar sights, parallels between your toy projects and real-world tools on the other side. And from these parallels, you slowly gain a better idea about what goes into those other once-enigmatic pieces of software and hardware.
Appendix A: Big Bugs
One thing that became readily apparent the deeper I got into the course was the difficulty of testing projects at higher levels in a holistic manner. The course, thankfully, only expects you to complete projects piecemeal rather than compiling entire programs down to binary. To compensate for this, there are many many tests your programs need to pass at each stage. Yet, in spite of all the testing, I always had a gnawing fear throughout the course that something I wrote 2 projects ago might still have a latent bug in it somewhere. If I were to realistically use this entire toolchain I wrote and something broke that was not supposed to, the bug could be layers deep or perhaps even the result of two bugs at different layers interacting in an unforeseen manner. In short, this would be a nightmare to debug. To combat this fear, industrial-grade pieces of software have a lot more attention and rigor thrust on them, and in the space of compilers, much effort goes not only into making the compiler but also proving that a compiler is correct. It is still, however, nerve-wracking to think about a bug existing at such a foundational level that it compromises all the software running above it.
While I have only been musing about accidental bugs so far, perhaps more scary are intentional ones. Ken Thompson famously wrote a lecture, Reflections on Trusting Trust, where he describes the potential threat of discreetly compromising the UNIX C compiler with a backdoor for the UNIX login command. The bugged compiler was designed to be able to replicate the backdoor even on subsequent compilations of clean compiler source. As long as one managed to set the bugged compiler up as the official C compiler, it would be nearly impossible to detect the bug without tracing the assembly output due to having circularly trusted the C compiler binary that was used to compile the compiler in the first place. Of course, this trust bubbles up. Anything that trusts the C compiler is compromised. Anything that trusts anything that trusts the C compiler is also compromised. Scary stuff.